Technical details
The website
The Tethys Forecasting System is based on open-source technology.
Its base programming language is Python, which offers the almost unique possibility of using a single language to program the data manangement and visualisation tool (the website) and
the scientific code required to prepare and run the forecasts.
The database behing Tethys is MySQL and Tethys itself runs on a Django web server.
To speed things up, the code at the heart of the forecasting system was written in openCL are performed in parallel using a Graphics Processing Unit (instead or in parallel to multiple CPU cores).
With this, years-worth of probabilistic forecasts can be computed in a matter of seconds.

Data
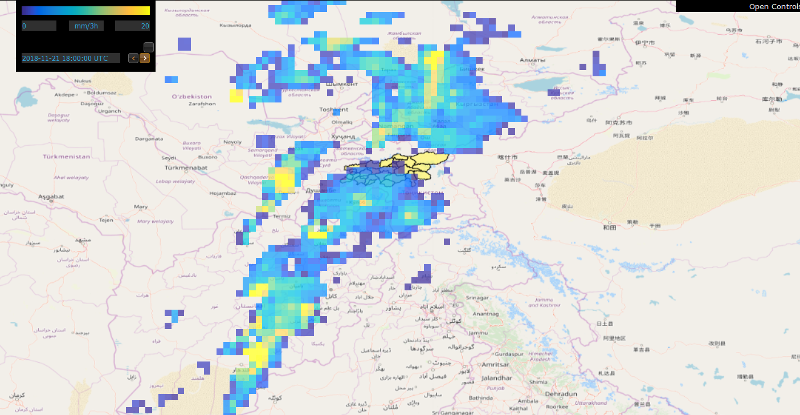
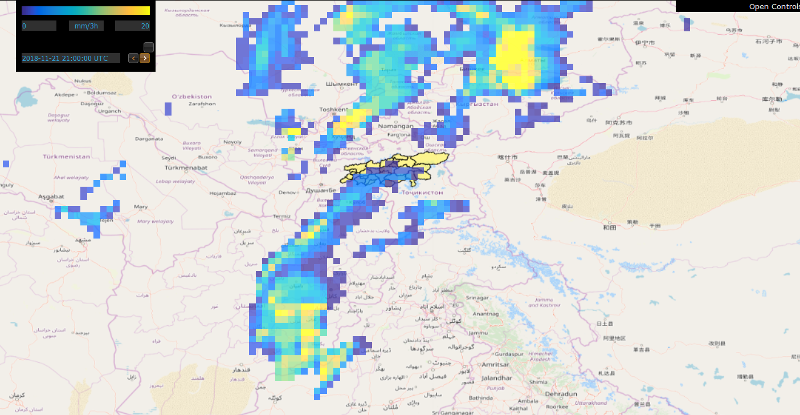
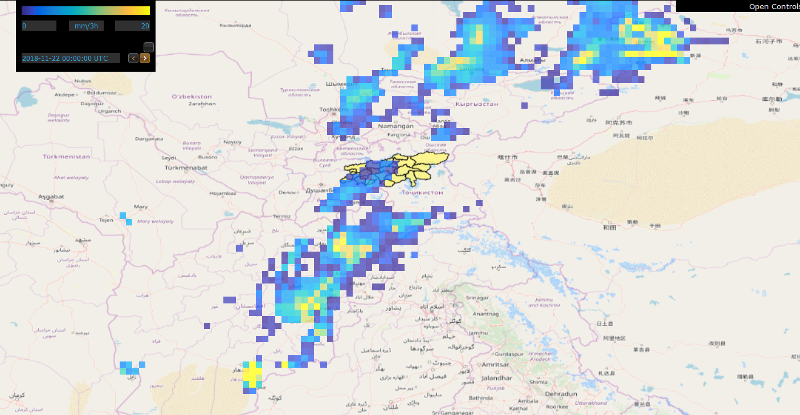
The system operates based on numerical weather forecasts and ground stations.
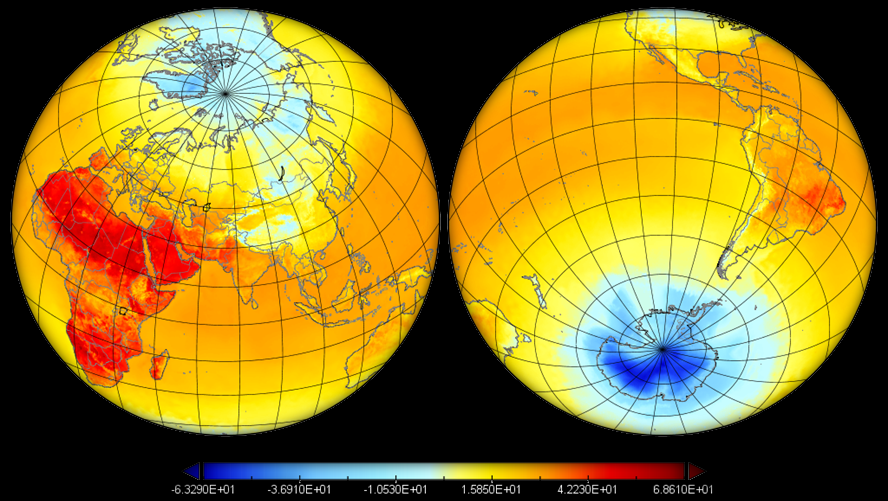
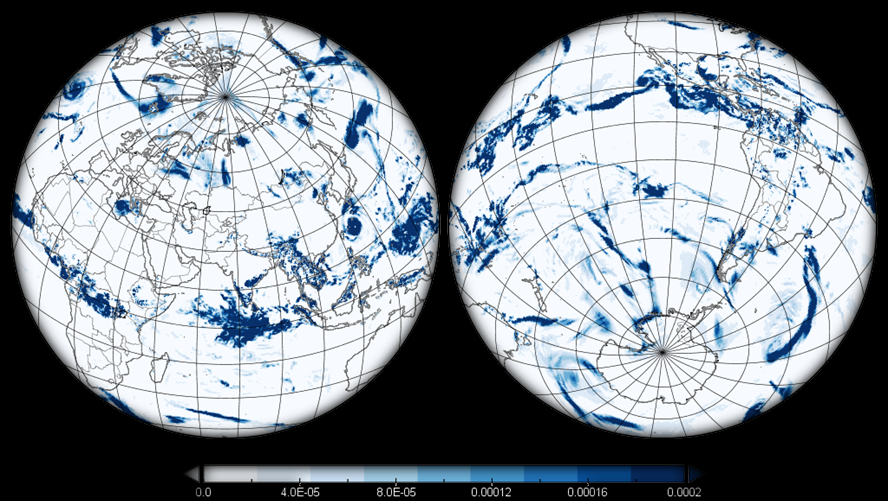
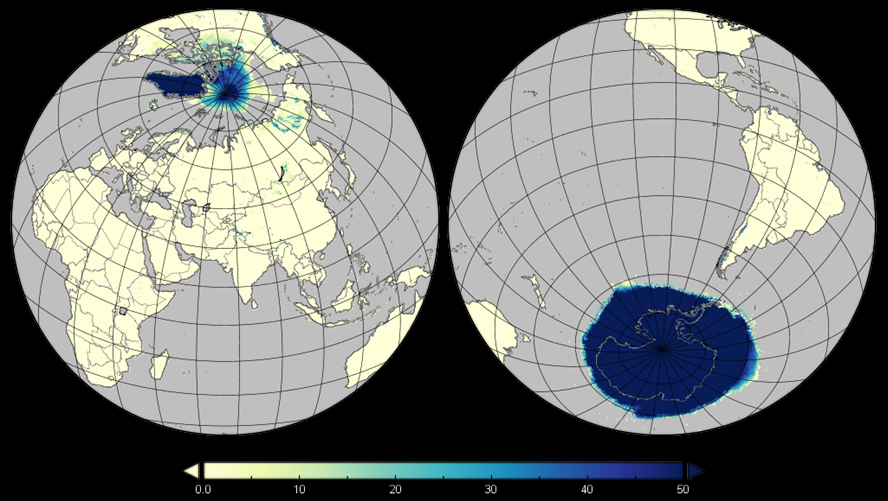
The weather forecast data comes from the Global Forecasting System (GFS) by the USA National Atmospheric and Oceanic Agengy (NOAA).
The forecasts go up to 16 days and are retrieved daily at a resolution of 0.5x0.5 deg.
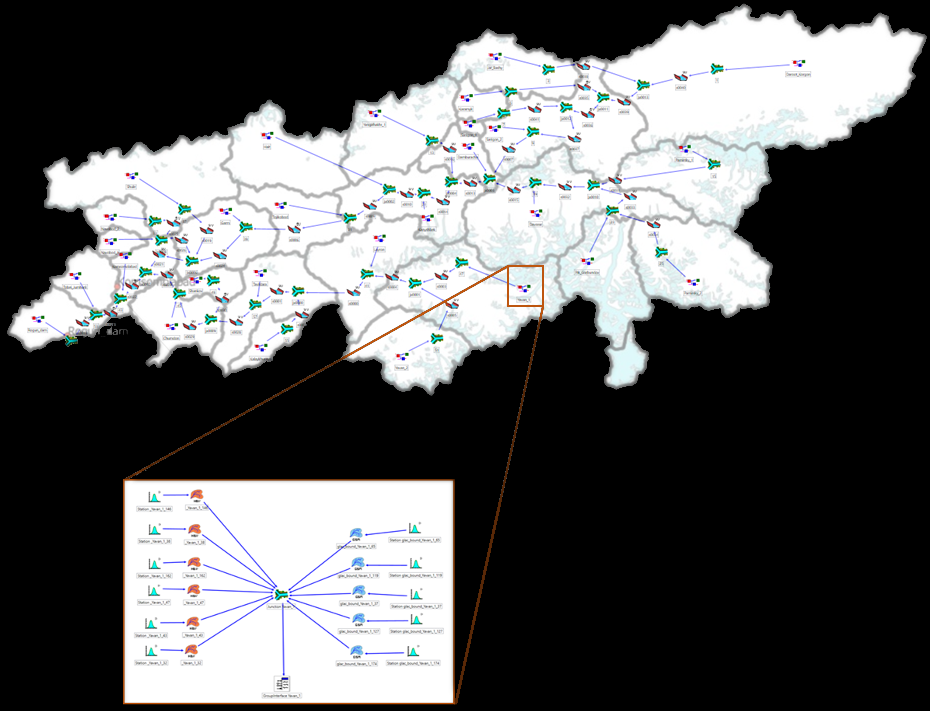
Ground data comes mainly from Tajik Hydromet, being complemented stations installed and operated directly by Salini Impregilo.
The database daily collects information from both automatic and manual weather and hydrometric stations within and in the vicinity of the
Vakhsh catchment.
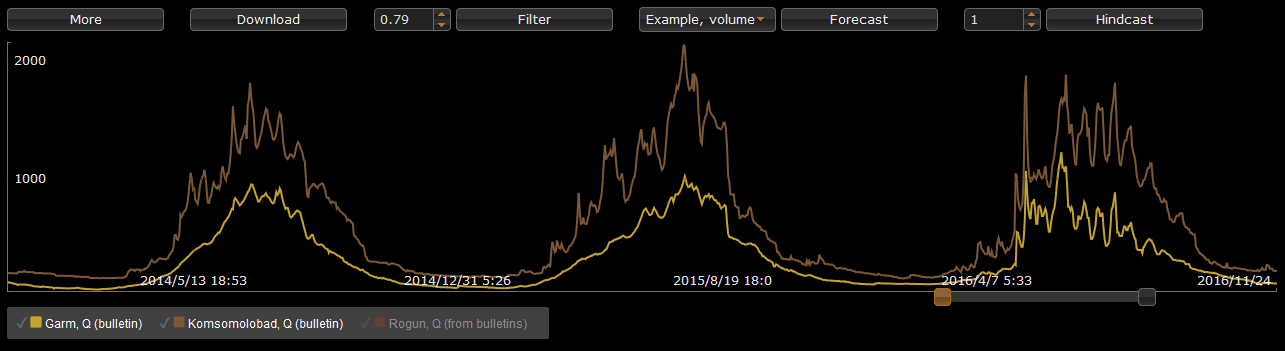
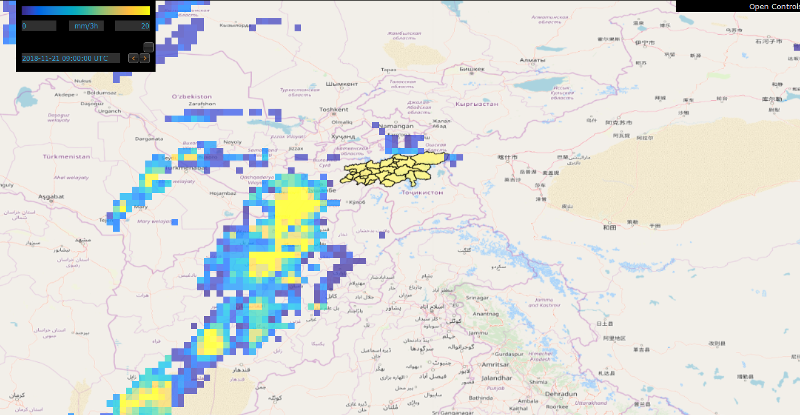
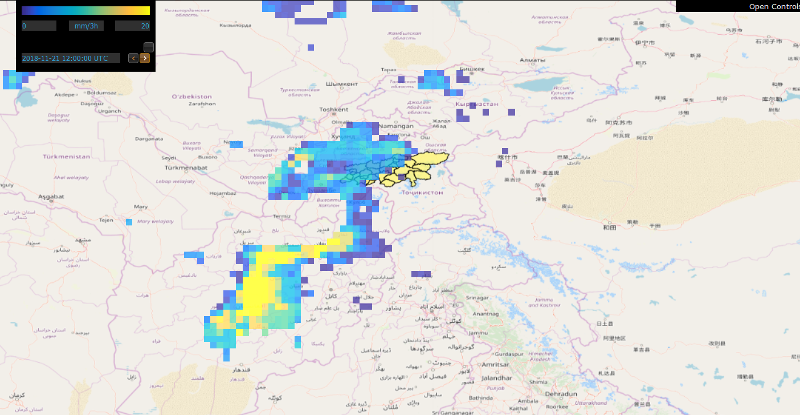
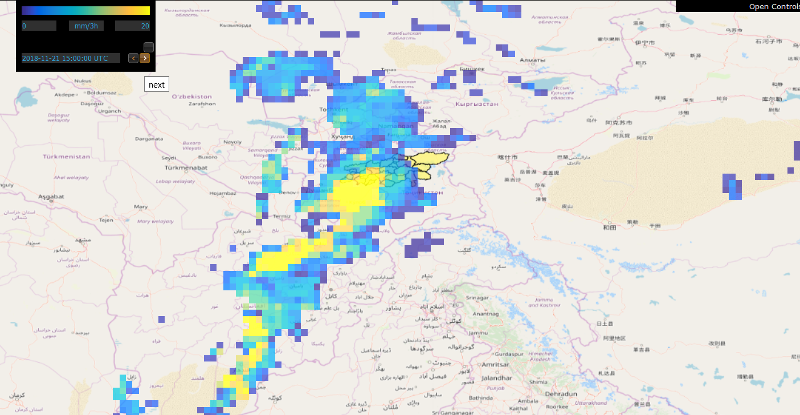
Below, examples of temperature, precipitation, and snow depth forecasts produced by GFS are displayed.
Hydrological modelling
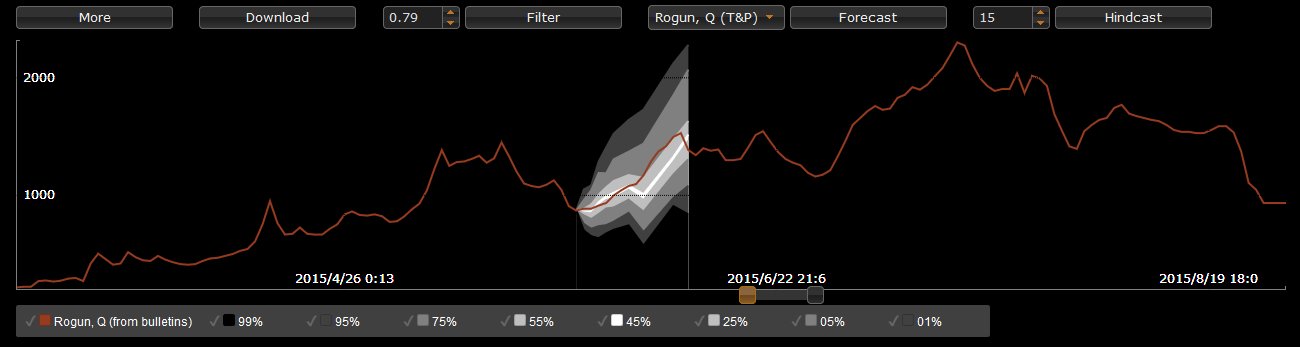
Optionally, the forecasts produced by Tethys can also benefit deterministic conceptual hydrologic models, reaping the best of the deterministic and probabilistic approaches.
In this adaptation for the Vakhsh, two such models are used: a degree-day factor snowmelt runoff (SMR) model
and RS-Minerve.
Both models were specifically calibrated for the Vakhsh and the second in particular includes a
filtering procedure whereby its internal states and parameters are automatically adapted in case of a large departure
from the observations.
The quality of the deterministic predictions is evaluated using the Nash-Sutcliffe Efficiency.
Below, the RS-Minerve hydrological model that was prepared for the Vakhsh Catchment is displayed.
Probabilistic forecasting
Probabilistic forecasting extends the traditional deterministic approach by associated uncertainty (i.e. potential errors) with every prediction.
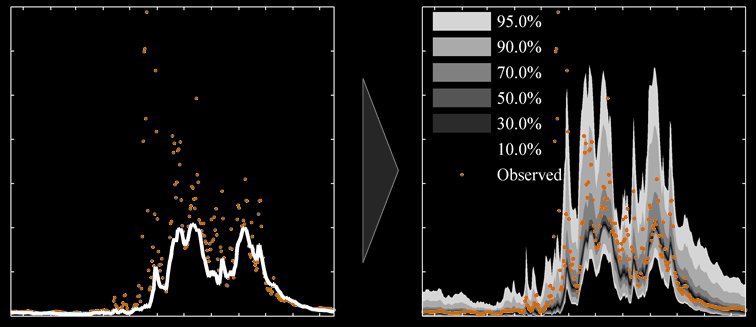
Doing so is not straightforward because the error is not always the same.
Predictive errors of hydrological series in particular are affected by issues such as heteroscedasticity (errors are usually greatest during high flows), non-normality (often hydrological probability distributions differ from the Gaussian distribution),
or autocorrelation (errors in consecutive timesteps are usually related, meaning that errors cannot be considered independent).
Such features render the implementation of analytical solutions for probabilistic forecasting impractical.
The previous points do not mean that attempts at estimating uncertainty are not usually made.
In fact, recognizing its importance, operational forecasting systems often include ways to model uncertainty.
In most cases, however, such efforts are computationally expensive and bounded by important modeling assumptions, leading only to rough estimations.
Fortunately, it is easy to assess whether a probabilistic prediction is reliable or not.
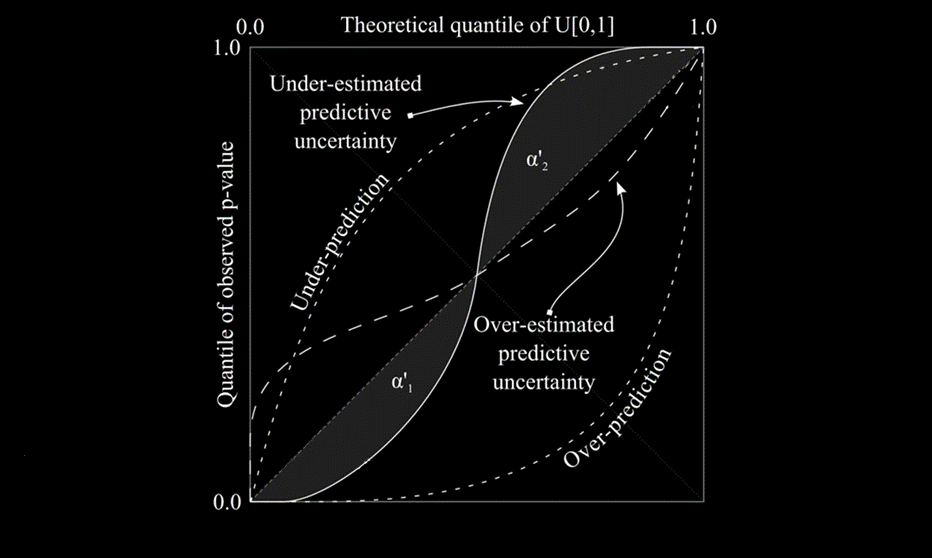
One way to do this is by computing a predictive quantile-quantile plot (see example below).
In a predictive quantile-quantile plot, a statistically reliable prediction will fall on a diagonal line.
Departures from that line indicate discrepancies between observations and the prediction and can be used to learn what may be wrong with the model.
Generalized Pareto Uncertainty
The probabilistic forecasting capabilities of Tethys are its distinguishing feature.
The Generalized Pareto Uncertainty algorithm used by Tethys does not assume much about the process being simulated, learning everything it needs
to know from historical data. Due to this, a large array of variables can be predicted if there is a sufficiently long historical series available (preferably 10 years or more).
GPU works by combining a very large number of regression models to produce its probabilistic forecasts.
Each one of these regression models is a deterministic function of the type y=f(X, W),
where X represents several input variables that may be used as inputs, and W is a matrix of model parameters.
For example, we may want to predict discharge one week from now based on today's observations of discharge,
temperature, and precipitation; that would look something like this: Qt+7=f([Qt, Tt, Pt], W).
The choice of an adequate regression model depends on the problem at hand.
To keep things general, an allowing Tethys to predict a wide range of variables, artificial neural networks were chosen.
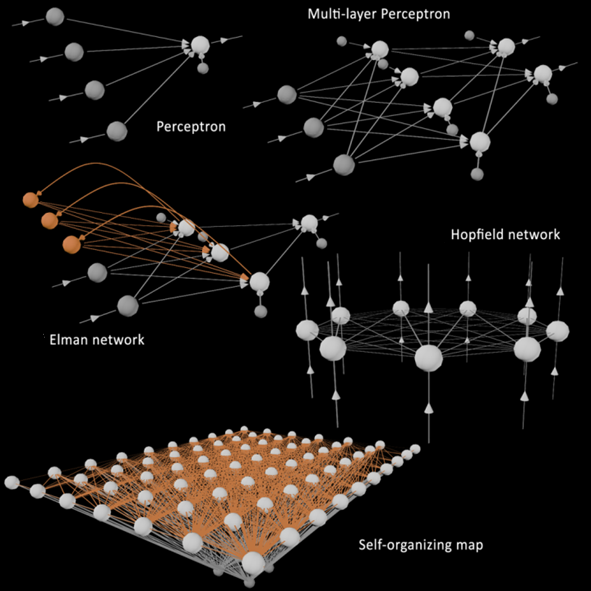
Artificial neural networks are machine learning or artificial intelligence models that come in different shapes and sizes (see figure below).
In Tethys, the multi-layer perceptron type was chosen.
These models emulate the human brain at a sub-symbolic level.
Based on layers of "neurons" and the "synapses" connecting them, multi-layer perceptrons can be trained with historical observations and learn to predict the behavior of complex systems.
But that was only one model. For a probabilistic prediction the Generalized Pareto Uncertanty combines thousands of such models, each with
its own specific parameters (W).
The key is to find the adequate parameters for each regression model f.
The Generalized Pareto Uncertanty uses a custom multi-objective optimization code that aims for:
1) each prediction being as close as possible to observations;
2) creating regression models that make predictions between always below obsevations to always above them.
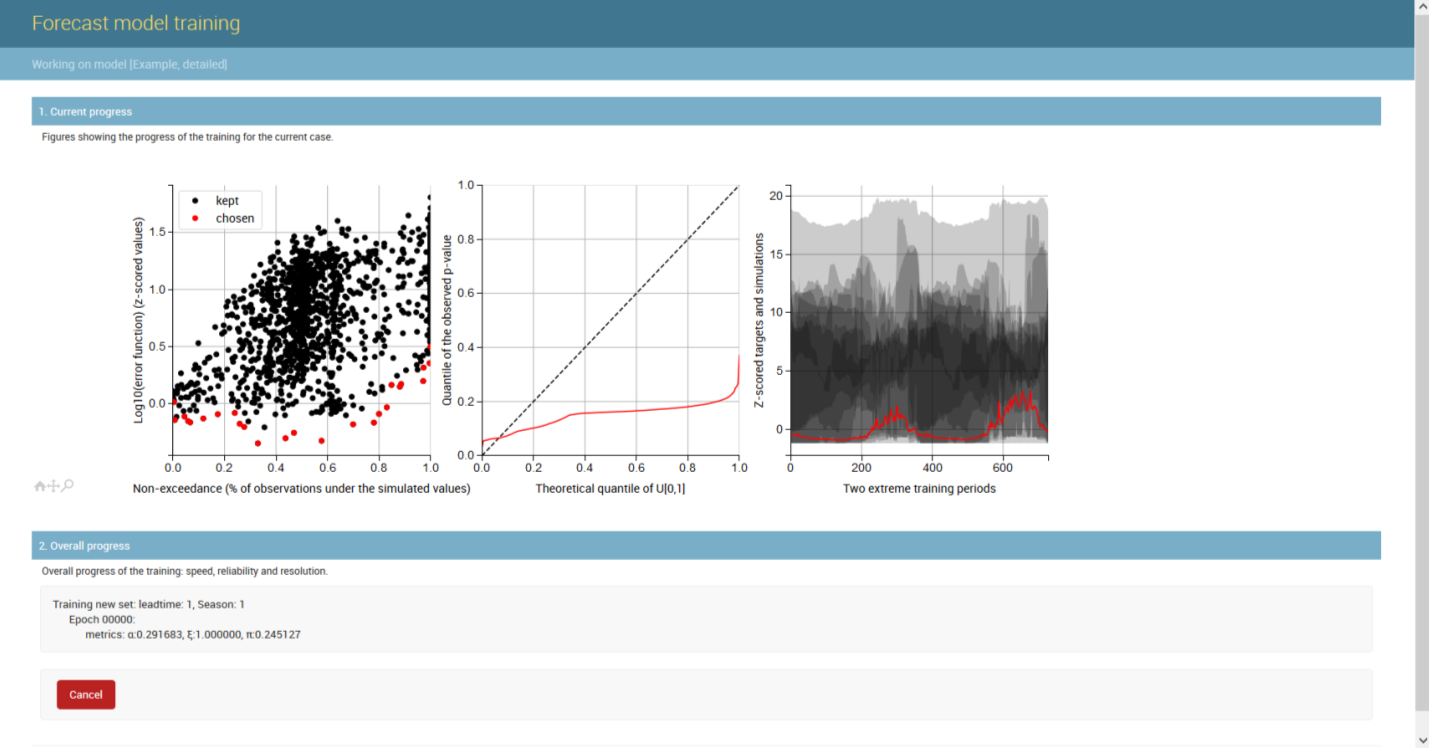
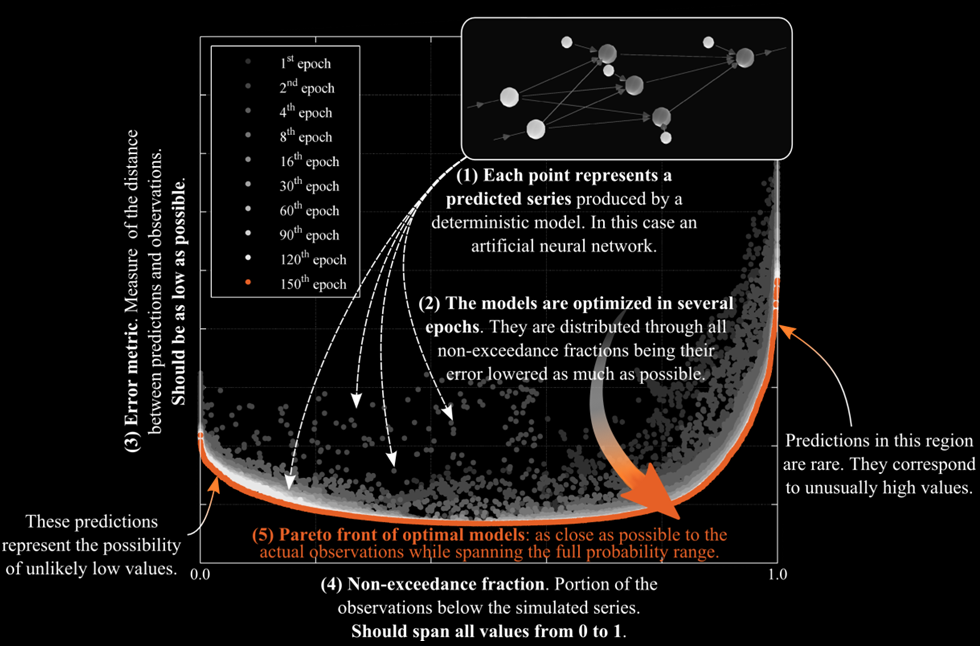
The training process is rather complicated (follow this link for further information), but it can be summarized in the figure below.
In the figure, each point represents a regression model (in this case an artificial neural network).
The x-axis represents non-exceedance, which can be related to probability.
For example, a non-exceedance of 0 means that, for the historical data set used to train the models, predictions were never exceeded by observations.
Conversely, a non-exceedance of 1 is obtained when historical predictions have consistently been above observations.
In order to guarantee that, for all non-exceedances, predictions are as close as possible to observations, it is important to account for the error associated with each model (y-axis).
Trough several epochs (or iterations) of training, the Generalized Pareto Uncertainty algorithm will find the sets of parameters that allow the many regression models to cover the full range of non-exceedances (from 0 to 1) with as little error as possible.
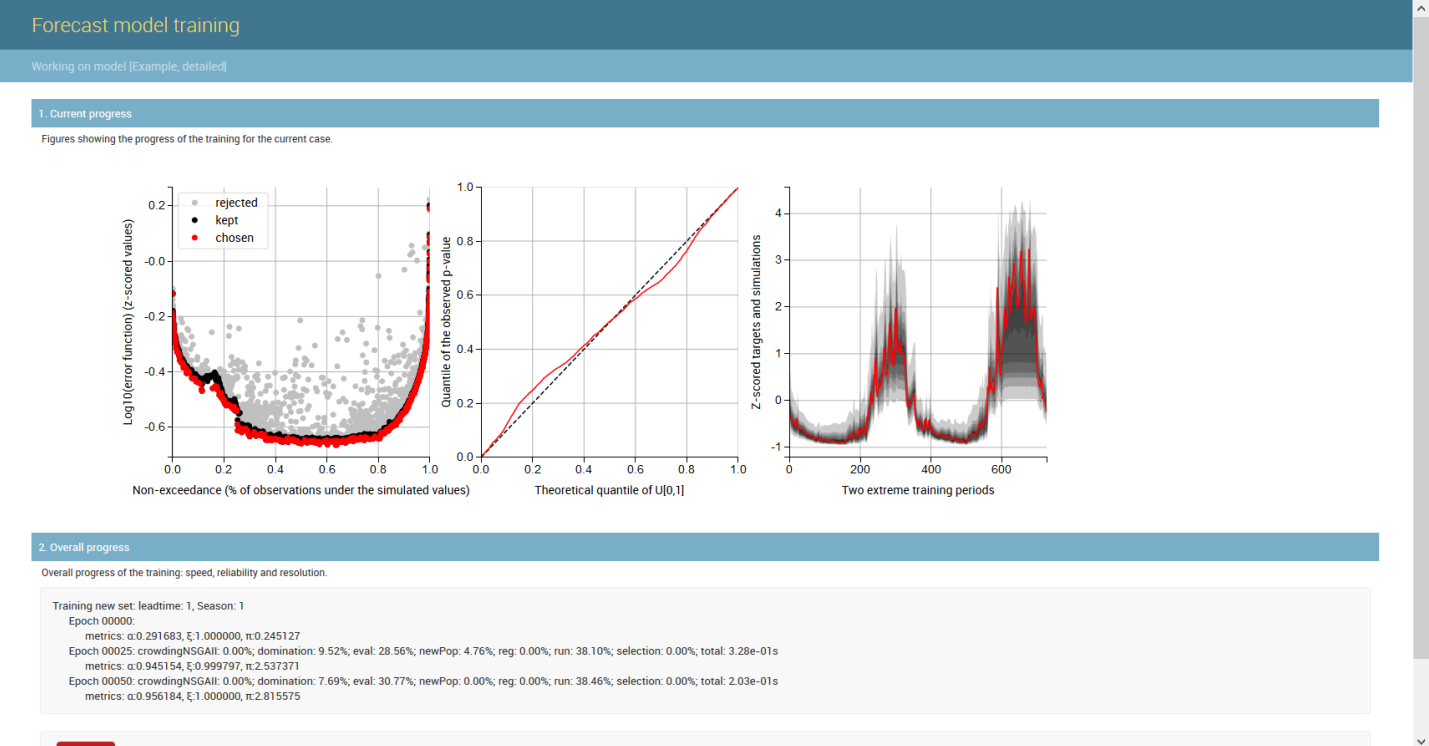
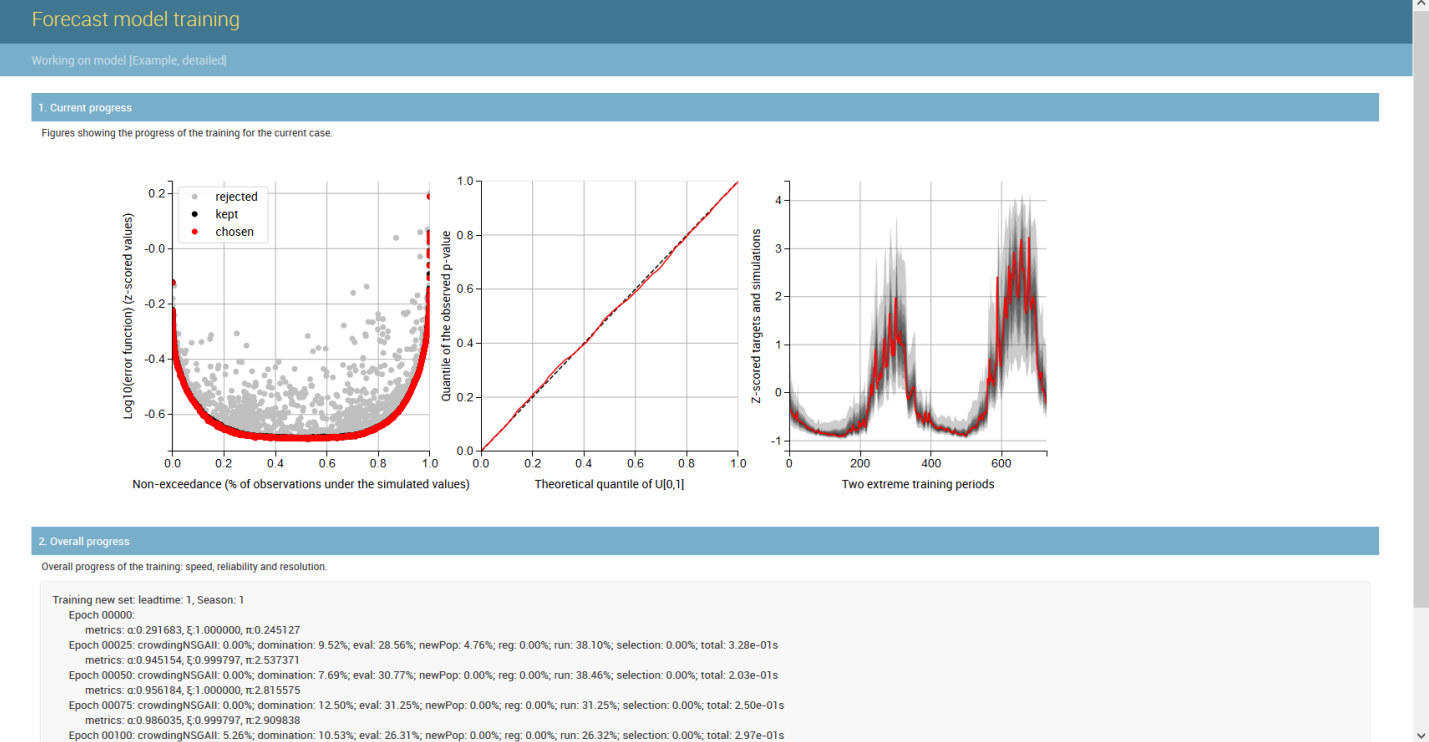
An example of the Generalizing Pareto Uncertainty model in the operation is shown below, where three figures illustrate the start, middle, and end phases of model training.
On the left plot the non-exceedance vs. error plane is portrayed;
in the middle, the quantile-quantile plot is displayed (perfect reliability along the diagonal); and
on the right plot the time series is shown (obsevations in red, probabilistic predictions in shaded gray).
When the training starts predictions are very bad (right plot) reliability is poor (middle plot).
As the training progresses (second figure), better parameters for each artificial neural network are found and predictive error is reduced (right plot).
Also, reliability is dramatically improved (middle plot) and predictions become much better (right plot).
When training is allowed to continue (third figure), the optimal parameters of reach artificial neural network will be found (left plot).
Reliability will typically be excellent (middle plot), and the uncertainty associated with the predictions is further reduced (right plot).